
티스토리 뷰
작성일: 2026년 2월 6일
카테고리: AI, LLM, Claude, Release
키워드: Claude Opus 4.6, Anthropic, 100만 토큰, Agent Teams, 적응형 사고, 벤치마크
요약
2026년 2월 5일, Anthropic이 Claude Opus 4.6을 출시했다. Opus 계열 최초로 100만 토큰 컨텍스트 윈도우(베타)를 지원하며, 에이전트 코딩 벤치마크에서 업계 최고 점수를 기록했다. Claude Code에는 여러 에이전트가 협업하는 Agent Teams 기능이 추가되었다. 이 글에서는 Opus 4.6의 주요 변경사항과 개발자에게 미치는 영향을 정리한다.
왜 Opus 4.6인가
Opus 4.5의 한계
Opus 4.5는 강력한 모델이었지만, 실무에서 두 가지 병목이 있었다.
첫째, 컨텍스트 윈도우 제한. 대규모 코드베이스를 다룰 때 200K 토큰은 충분하지 않았다. 수십 개 파일을 동시에 참조해야 하는 리팩토링 작업에서 모델이 앞서 읽은 파일의 내용을 "잊어버리는" 현상(컨텍스트 열화)이 빈번했다.
둘째, 장시간 에이전트 작업의 불안정성. 복잡한 디버깅이나 멀티스텝 작업에서 중간에 방향을 잃거나, 이전 단계의 결정을 번복하는 경우가 있었다.
Opus 4.6은 이 두 가지 문제를 정면으로 해결한다.
핵심 변경사항
1. 100만 토큰 컨텍스트 윈도우 (베타)
Opus 계열 최초로 100만(1M) 토큰 컨텍스트를 지원한다.
숫자를 체감하기 쉽게 비유하면, 200K 토큰이 단행본 한 권이라면 1M 토큰은 백과사전 한 질에 해당한다. 대규모 코드베이스 전체를 한 번에 읽고 추론할 수 있다.
단순히 창을 넓힌 것이 아니라 장거리 정보 검색 정확도도 크게 개선되었다.
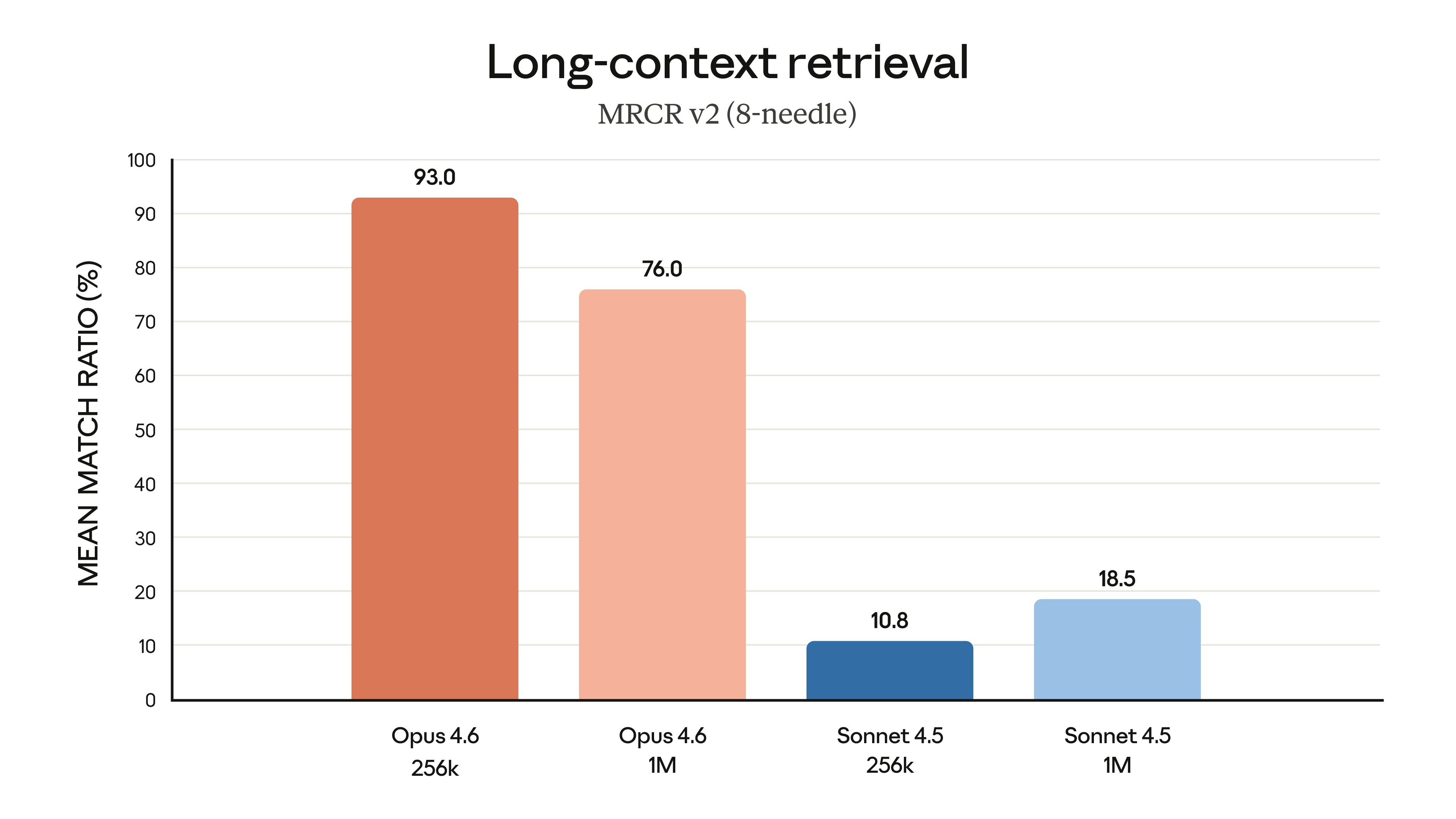
출처: Anthropic - Claude Opus 4.6
MRCR v2 벤치마크(8-needle, 1M 컨텍스트)에서 결과가 이를 증명한다:
| 모델 | MRCR v2 (8-needle 1M) |
|---|---|
| Opus 4.6 | 76% |
| Sonnet 4.5 | 18.5% |
100만 토큰 문서에서 8개의 핵심 정보를 정확히 찾아내는 테스트에서, Opus 4.6은 Sonnet 4.5 대비 4배 이상의 정확도를 보인다. 컨텍스트가 넓어진 만큼 "읽었지만 기억 못하는" 문제가 대폭 줄어든 것이다.
2. 적응형 사고 (Adaptive Thinking)
이전 모델에서는 확장 사고(Extended Thinking)를 켜거나 끄는 이분법적 선택만 가능했다. 간단한 질문에도 깊은 추론을 수행하면 비용과 지연이 불필요하게 증가했다.
Opus 4.6의 적응형 사고는 질문의 난이도에 따라 추론 깊이를 자동 조절한다. 에어컨의 자동 모드와 비슷하다. 온도가 높으면 강하게, 이미 적정 온도면 약하게 가동하듯, 단순 질문에는 빠르게 답하고 복잡한 문제에만 깊이 사고한다.
개발자는 노력 수준(effort level)을 4단계로 조절할 수 있다:
| 수준 | 용도 | 비용/속도 |
|---|---|---|
| 낮음 | 단순 분류, 포맷 변환 | 최저 비용, 최고 속도 |
| 중간 | 일반적인 코드 생성 | 균형 |
| 높음 (기본값) | 복잡한 디버깅, 설계 | 균형 |
| 최대 | 수학 증명, 보안 분석 | 최고 비용, 최저 속도 |
3. 에이전트 코딩 성능 향상
Opus 4.6은 코딩 영역에서 가장 눈에 띄는 개선을 보인다:
- 신중한 계획 수립: 코드 작성 전 설계 단계에서의 추론 품질 향상
- 장시간 작업 지속성: 복잡한 멀티스텝 작업에서 방향을 유지
- 대규모 코드베이스 안정성: 수만 줄 규모의 프로젝트에서도 일관된 품질
- 코드 리뷰 및 디버깅: 버그 원인 추적과 수정 제안의 정확도 향상
벤치마크 성과
다음은 Opus 4.6과 주요 프론티어 모델의 벤치마크 비교표다.
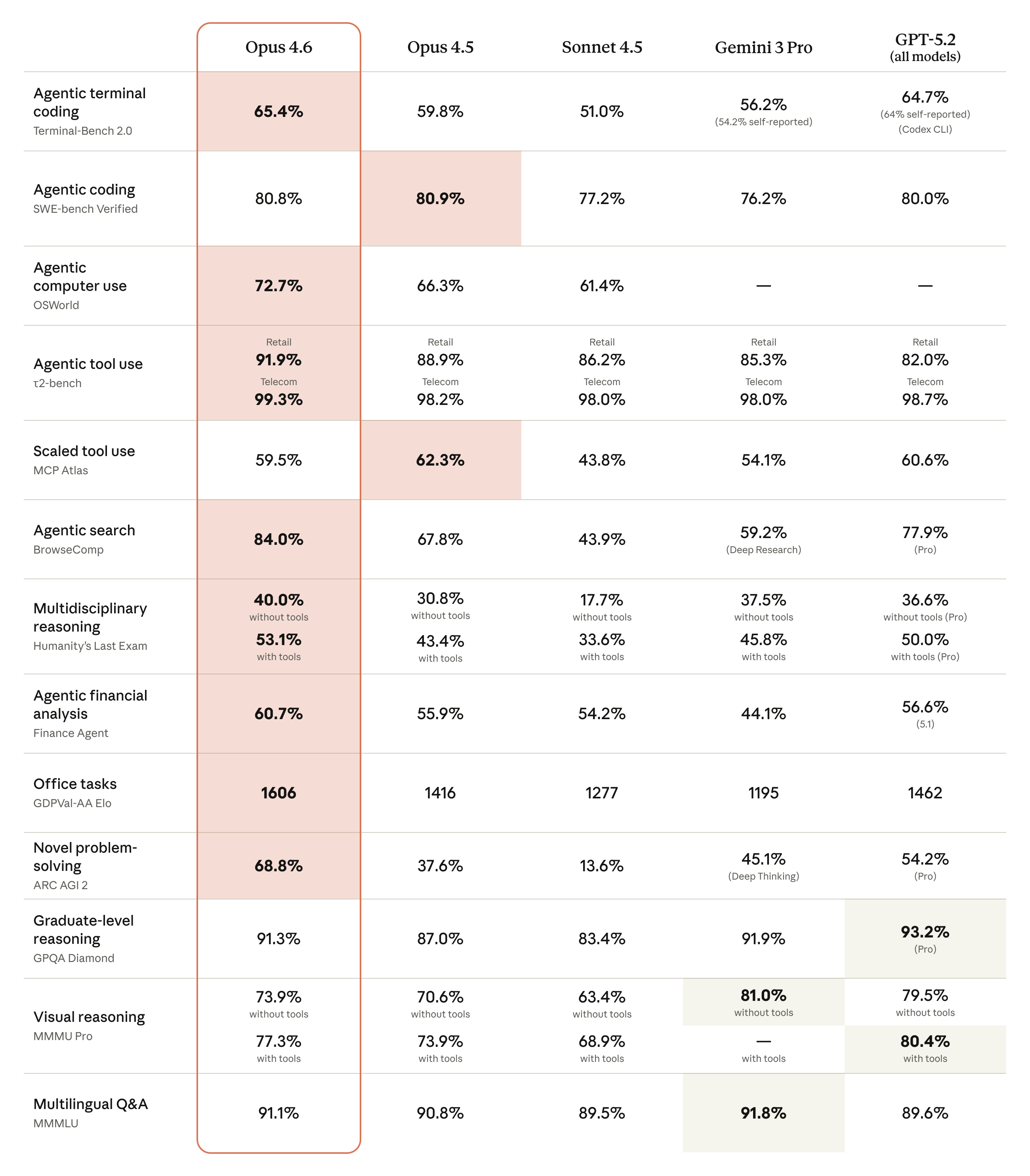
출처: Anthropic - Claude Opus 4.6
핵심 수치를 요약하면 다음과 같다:
| 벤치마크 | 측정 대상 | Opus 4.6 | Opus 4.5 | GPT-5.2 |
|---|---|---|---|---|
| Terminal-Bench 2.0 | 자율 에이전트 코딩 | 65.4% | 59.8% | 64.7% |
| SWE-bench Verified | 에이전트 코딩 | 80.8% | 80.9% | 80.0% |
| OSWorld | 컴퓨터 사용 | 72.7% | 66.3% | - |
| BrowseComp | 정보 검색 | 84.0% | 67.8% | 77.9% |
| Humanity's Last Exam | 다분야 추론 (도구 사용) | 53.1% | 43.4% | 50.0% |
| GDPval-AA | 사무 업무 (Elo) | 1606 | 1416 | 1462 |
| ARC AGI 2 | 신규 문제 해결 | 68.8% | 37.6% | 54.2% |
| GPQA Diamond | 대학원 수준 추론 | 91.3% | 87.0% | 93.2% |
몇 가지 주목할 지점이 있다.
에이전트 영역에서 압도적 우위. Terminal-Bench 2.0(자율 터미널 코딩), OSWorld(컴퓨터 사용), BrowseComp(정보 검색) 등 에이전트가 자율적으로 행동하는 벤치마크에서 전 모델 중 최고 점수를 기록했다.
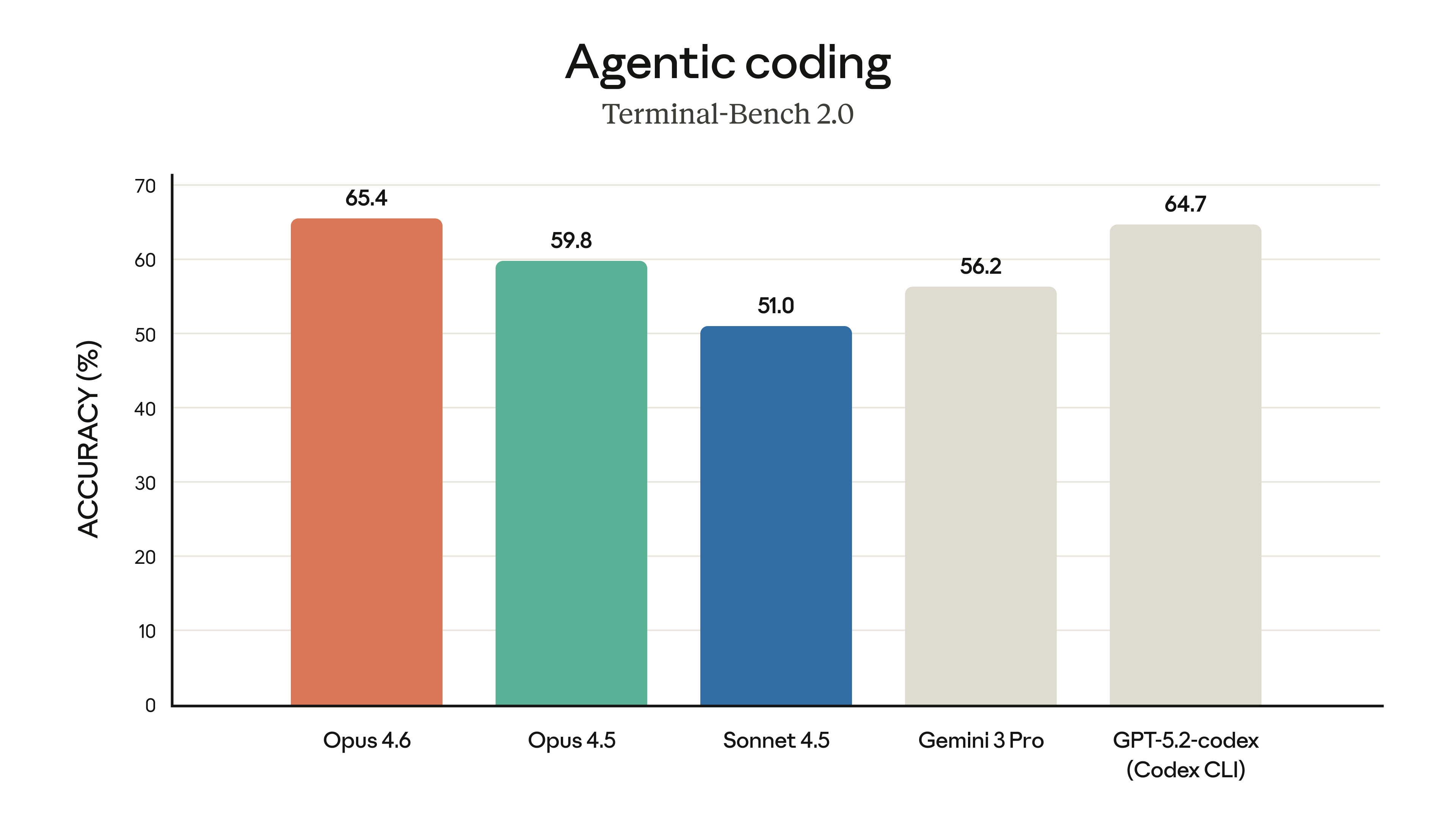
출처: Anthropic - Claude Opus 4.6
특히 BrowseComp는 Opus 4.5 대비 16.2%p 상승으로, 검색 기반 에이전트 작업에서의 도약이 크다.
사무 업무에서의 격차. GDPval-AA(금융/법률 업무)에서 Opus 4.5보다 190 Elo, GPT-5.2보다 144 Elo 높은 1606점을 기록했다.
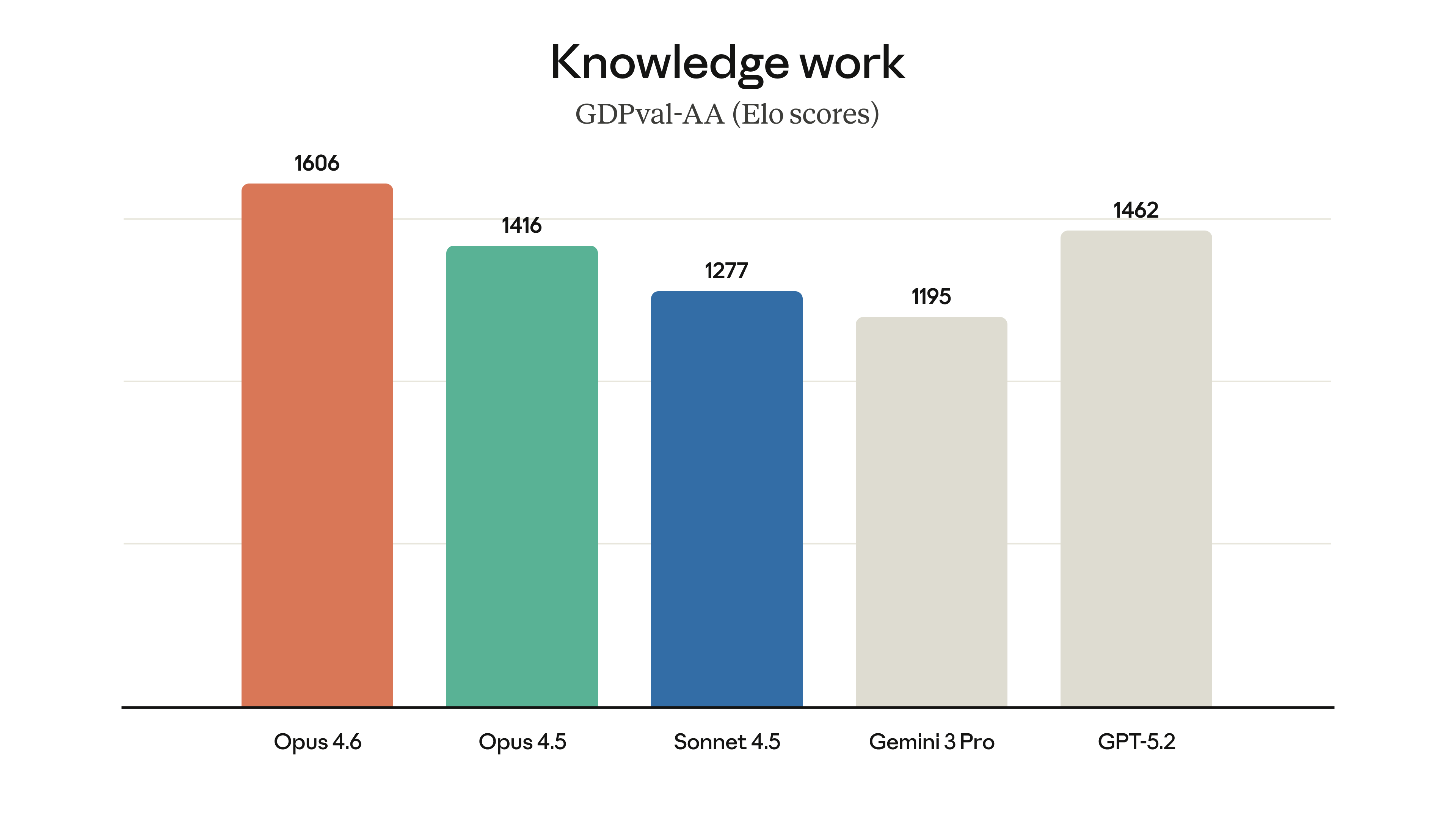
출처: Anthropic - Claude Opus 4.6
금융 분석, 법률 문서 검토 등 실무 영역에서의 성능이 한 단계 올라간 것이다.
ARC AGI 2에서 거의 2배 성장. 새로운 유형의 문제를 풀어내는 능력을 측정하는 ARC AGI 2에서 37.6% → 68.8%로 뛰었다. 단순 패턴 매칭이 아닌 추상적 추론 능력이 크게 향상되었음을 보여준다.
SWE-bench에서는 Opus 4.5가 근소 우위. 에이전트 코딩(SWE-bench Verified)에서는 Opus 4.5(80.9%)가 Opus 4.6(80.8%)을 0.1%p 앞선다. 모든 벤치마크에서 일방적 우위가 아닌 점은 참고할 필요가 있다.
생명과학 벤치마크에서 약 2배 성장. 계산생물학, 구조생물학, 유기화학 영역에서 Opus 4.5 대비 약 2배 수준의 성능 향상이 보고되었다.
Claude Code 업데이트
Opus 4.6 출시와 함께 Claude Code v2.1.32가 릴리즈되었다. 가장 주목할 만한 기능은 Agent Teams다.
Agent Teams (연구 미리보기)
하나의 작업을 여러 에이전트가 나눠서 처리하는 멀티에이전트 협업 기능이다.
회사에서 프로젝트를 진행할 때 한 사람이 모든 것을 하는 것보다 역할을 나누는 것이 효율적인 것처럼, Agent Teams는 여러 에이전트가 병렬로 작업하고 자율적으로 협업한다.
활성화 방법:
CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1 claudeShift+위/아래 키 또는 tmux로 개별 에이전트를 제어할 수 있다. 다만, 토큰 소비가 많으므로 Max 요금제 또는 API 사용자에게 적합하다.
자동 메모리
작업 중 학습한 내용을 자동으로 기록하고 다음 세션에서 회상하는 기능이다. 메모리 스코프를 user, project, local 중 선택할 수 있다.
매번 같은 프로젝트 컨텍스트를 설명할 필요가 줄어든다.
컨텍스트 컴팩션 (베타)
긴 대화에서 토큰 임계값에 도달하면, 이전 컨텍스트를 자동으로 요약하여 압축하는 기능이다. 책을 읽다가 앞부분의 핵심만 메모해두고 이어서 읽는 것과 비슷하다.
1M 컨텍스트 윈도우와 결합하면, 매우 긴 에이전트 세션에서도 핵심 정보를 유지하면서 작업을 지속할 수 있다.
기타 개선사항
- 부분 대화 요약: 대화 전체가 아닌 특정 지점부터 요약 가능
- Skills 자동 로드:
--add-dir로 추가한 디렉토리의.claude/skills/도 자동 인식 - 서브에이전트 제한 설정: 특정 에이전트 타입만 사용하도록 제한 가능
- 새 Hook 이벤트:
TeammateIdle,TaskCompleted이벤트 추가
Office 통합
Claude in Excel
대규모 스프레드시트에서 계획 수립, 비정형 데이터 구조화, 다단계 분석을 수행한다. Opus 4.6의 장시간 작업 지속성 덕분에 복잡한 재무 모델링도 안정적으로 처리할 수 있게 되었다.
Claude in PowerPoint (연구 미리보기)
데이터 기반 발표 자료를 자동 생성한다. 브랜드 일관성을 유지하면서 차트와 텍스트를 구성하는 것이 특징이다.
가격
가격은 Opus 4.5와 동일하다:
| 구분 | 가격 (백만 토큰당) |
|---|---|
| 입력 | $5 |
| 출력 | $25 |
| 입력 (200K 초과 프롬프트) | $10 |
| 출력 (200K 초과 프롬프트) | $37.50 |
최대 출력은 128,000 토큰이다. 미국 전용 추론 옵션을 사용할 경우 토큰 가격에 1.1배가 적용된다.
가격은 동일하지만 장시간 작업 안정성이 향상되어 재시도 빈도가 줄어든 점을 고려하면 실질적인 비용 효율은 개선되었다고 볼 수 있다.
안전성
Opus 4.6은 부적절 행동(속임수, 망상 조장, 악용 협조) 비율이 감소했으며, 무해한 질문을 잘못 거부하는 과잉 거부(over-refusal) 비율이 프론티어 모델 중 최저를 기록했다.
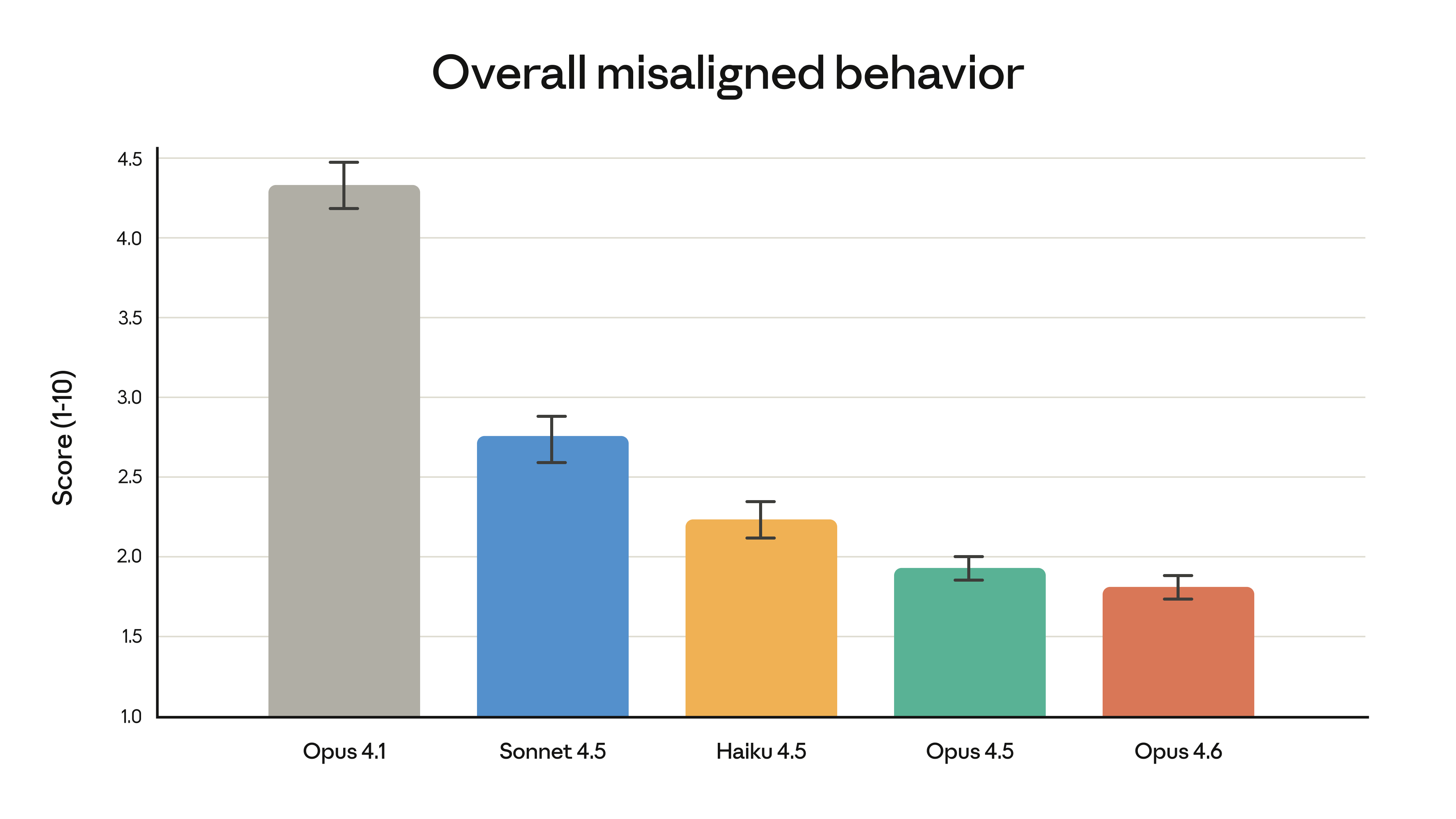
출처: Anthropic - Claude Opus 4.6
6가지 신규 사이버보안 탐지 테스트가 추가되어, 안전성 평가 범위도 확대되었다.
사용 방법
API
import anthropic
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-opus-4-6",
max_tokens=1024,
messages=[
{"role": "user", "content": "Hello, Opus 4.6"}
]
)Claude Code에서 1M 컨텍스트 사용하기
Claude Code는 기본적으로 200K 토큰 컨텍스트로 동작한다. 1M 컨텍스트를 사용하려면 [1m] 접미사를 명시해야 한다:
# 세션 시작 시 1M 컨텍스트로 실행
claude --model opus[1m]
# 세션 도중 전환
/model opus[1m]
# Sonnet에도 적용 가능
/model sonnet[1m]200K를 초과하는 프롬프트에는 프리미엄 요금(입력 2배, 출력 1.5배)이 적용된다. 대규모 코드베이스 분석이나 장시간 에이전트 세션에서 유용하지만, 일반적인 작업에서는 기본 200K로 충분하다.
사용 가능 플랫폼
- claude.ai (Pro, Team, Enterprise)
- Anthropic API (
claude-opus-4-6) - GitHub Copilot (Pro, Pro+, Business, Enterprise)
- Amazon Bedrock
- Google Cloud Vertex AI
실무에서 의미하는 것
Opus 4.6의 변화를 한 문장으로 요약하면: "더 오래, 더 넓게, 더 정확하게"다.
| 영역 | Opus 4.5 | Opus 4.6 |
|---|---|---|
| 컨텍스트 | 200K | 1M (베타) |
| 장문맥 검색 | 제한적 | MRCR v2 76% |
| 에이전트 작업 | 단일 | 멀티에이전트 (Agent Teams) |
| 사고 방식 | ON/OFF | 적응형 (4단계) |
| 노력 수준 조절 | 미지원 | 4단계 세밀 조정 |
| 컨텍스트 관리 | 수동 | 자동 컴팩션 (베타) |
| GitHub Copilot | 지원 | GA (전 플랫폼) |
대규모 리팩토링, 멀티서비스 디버깅, 장문 문서 분석처럼 기존에 모델의 한계로 어려웠던 작업이 실질적으로 가능해진다. 특히 Agent Teams는 AI 코딩 워크플로우의 패러다임을 바꿀 잠재력이 있다. 한 에이전트가 테스트를 작성하는 동안 다른 에이전트가 구현을 진행하는 식의 병렬 개발이 가능해지기 때문이다.
얼리 액세스 파트너 반응
Opus 4.6을 사전 테스트한 파트너들의 피드백도 주목할 만하다:
- Notion: 자율적 작업 실행 능력에서 유의미한 개선
- GitHub: Copilot에서의 복잡한 문제 해결 능력 향상
- Replit: 에이전트 코딩 시나리오에서의 성능 도약
- Asana: 엔터프라이즈 워크플로우 자동화에서의 정확도 개선
특히 GitHub은 출시 당일 GitHub Copilot에서 Opus 4.6을 일반 제공(GA)으로 전환했다. VS Code, Visual Studio, github.com, GitHub Mobile, GitHub CLI 등 전 플랫폼에서 모델 선택기를 통해 사용할 수 있다.
참고 자료
공식 문서
플랫폼 공지
관련 블로그
'실제 경험과 인사이트를 AI와 함께 정리한 글' 카테고리의 다른 글
| GitHub Superpowers v1.1.0: Agent Team 오케스트레이션과 Plan Mode (0) | 2026.02.07 |
|---|---|
| Claude Code Agent Teams: 여러 AI가 함께 코딩하는 시대 (0) | 2026.02.06 |
| Claude Code v2.1.31 Windows 입력 불가 버그: stdin Race Condition 해결하기 (0) | 2026.02.05 |
| GitHub Superpowers: Claude Code에서 설계부터 PR까지 자동 추적하기 (0) | 2026.02.04 |
| Superpowers 플러그인: Claude Code를 체계적인 개발 파트너로 만드는 방법 (0) | 2026.02.03 |
- Total
- Today
- Yesterday
- Go
- claude code
- Ontology
- api gateway
- LangChain
- troubleshooting
- AI agent
- Kubernetes
- Next.js
- Tailwind CSS
- react
- security
- architecture
- frontend
- Developer Tools
- Rag
- AI Development
- 개발 도구
- authentication
- authorization
- Claude
- LLM
- PYTHON
- Developer Productivity
- AI
- SHACL
- knowledge graph
- workflow
- backend
- ai 개발 도구
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |